10 Solid Tips for Better Caching Practices
Caching can be an effective method of improving API performance by reducing latency and resource utilization. However, things have drawbacks, especially in system design. So here are 10 things you must keep in mind while implementing caching, listed concisely.
By doing this, you will be able to manage caching operations systematically, ensure reliability, and improve the security of your services.
If you are new to the caching method, check out my previous blog.
I am jumping straight into the points and will cover everything concisely to save you time. I will be using Golang for any examples, which is a very easy-to-understand language, and you can use the same concepts in languages of your choice. The database of my choice will be Redis, which dominates the caching world.
Setting Expiry Times (TTL)
TTL stands for time to live, which, in this context, is the time for cached data to persist in the database. This ensures that any entry in the cache database is deleted after a set time. There are a couple of benefits it provides:
- The most basic way of invalidating stale data.
- Freeing up the limited space in the in-memory caching database.
- Ensure requests made after a long time are updated from the primary database to ensure data is updated.
err := redisClient.Set(ctx, "key", "value", time.Minute).Err()
if err != nil {
log.Fatalf("Failed to set key: %v", err)
}
You can change the value of TTL to adjust the freshness of your data. Databases like Redis are equipped with expiration timers, so you don’t need to perform delete operations manually.
Using Cache Invalidation
Explicitly invalidating data as soon as an update is made on the primary database ensures that the service doesn’t end up serving older data.
Doing this has a couple of benefits over security and user experience:
- It prevents users from dealing with old data that they just updated. This is useful when you are serving user-controlled dynamic data.
- Older data can cause security issues. For example, if you block a user, a non-updated cache can unintentionally authorize access.
You can delete a key in Redis by:
err := redisClient.Del(ctx, "key").Err()
if err != nil {
log.Fatalf("Failed to delete key: %v", err)
}
It’s better to delete the data than to update it since it makes the system read the data from the primary database and perform write operations on the caching database, which is resource-intensive.
A notification from the primary database about an update and delete operation on the caching database is usually less computationally intensive.
This process can be done asynchronously, and in the case of Golang, goroutines can prove useful.
Write-Through Cache
In certain cases, when the data is user-controlled and isn’t changed frequently (and in rare cases, not serving that data causes the whole chain of data to slow down), you would need to update the cache.
func UpdateData(ctx context.Context, key string, value string) error {
err := db.Update(key, value)
if err != nil {
return err
}
return redisClient.Set(ctx, key, value, time.Minute).Err()
}
In this case, the updating cache mechanism can be done asynchronously, depending upon the requirements.
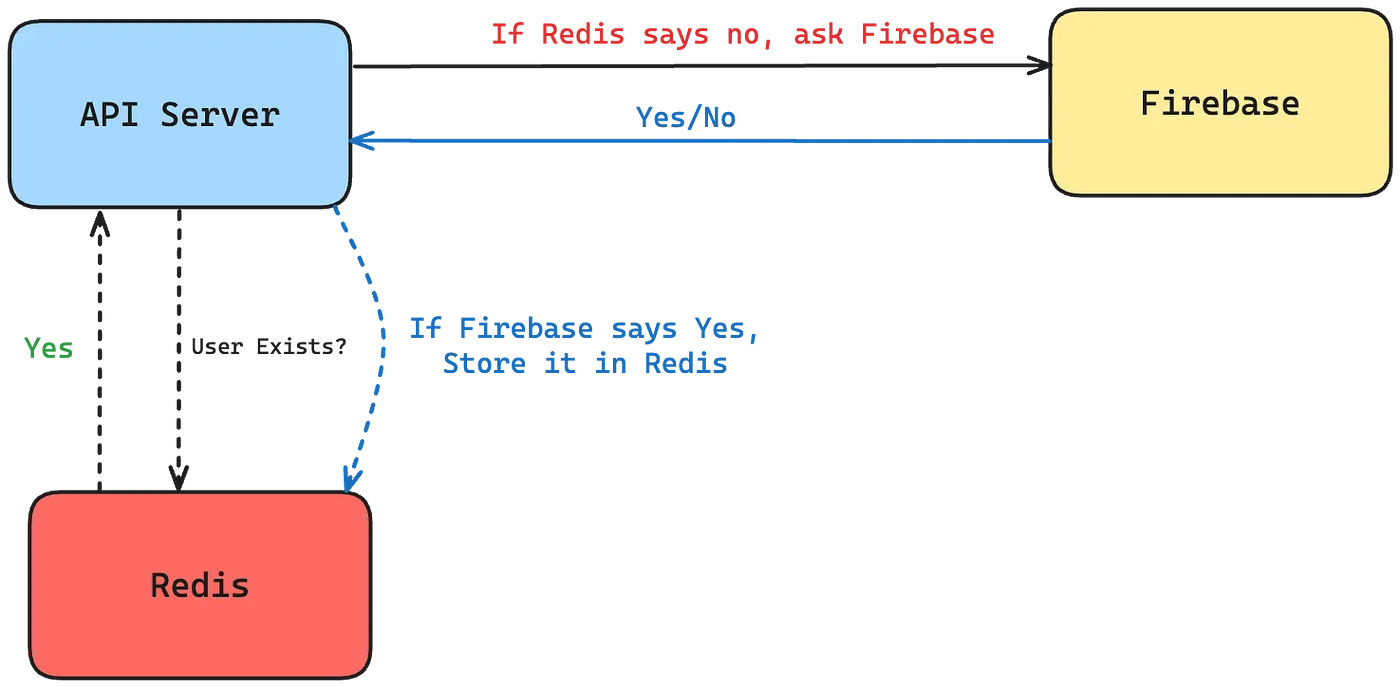
Read-Through Cache
When data is needed to be fetched, first query the caching database. If the cache is missed, fetch the data from the primary database and write it to the cache asynchronously.
func GetData(ctx context.Context, key string) (string, error) {
val, err := redisClient.Get(ctx, key).Result()
if err == redis.Nil {
// Cache missed! fetch from DB
val, err = db.Get(key)
if err != nil {
return "", err
}
// Update the cache
go redisClient.Set(ctx, key, val, time.Minute)
} else if err != nil {
return "", err
}
return val, nil
}
This is a basic checkpoint, but it’s necessary to remember so you don’t forget asynchronous updating and end up writing the cache database procedurally and causing latency.
Cache Busting with Versioned Keys
Appending a version or timestamping cached keys can be a way to invalidate stale data. This ensures that outdated keys are ignored.
versionedKey := fmt.Sprintf("key:%d", currentVersion)
redisClient.Set(ctx, versionedKey, "value", time.Minute)
When hitting the cache, you can append the version number (or timestamp) and check the value.
Background Cache Refresh
There are two ways you can achieve a background refresh mechanism:
- Lazy: Refresh cache data with the primary database when a cache miss occurs.
- Proactive: Refresh cache data with the primary database after a set interval with a background job or service. This is more useful in cases where you have the whole primary database mirrored into a cache database.
Distributed Locking
Distributed Locking is used to prevent race conditions.
Race conditions occur when multiple services or processes try to access the data simultaneously. This can have serious consequences and crash the backend services.
In our example, if multiple processes interact with Redis, use distributed locks (e.g., using SETNX or Redlock) to ensure only one process updates the cache at a time, avoiding race conditions.
Implementing Cache Consistency Policies
Choosing consistent caching policies depending on the applications is strategically advantageous. Basically, there are 2 ways you can proceed.
- Strong Consistency: Always update the cache on database changes, which is resource-intensive.
- Eventual Consistency: Allow slight delays in synchronization, useful for performance.
Planning this before building the application can save you a lot of debugging and fixes.
Monitoring and Tuning Cache Usage
As important as monitoring backend processes and microservices, ensuring these little caching databases get enough attention is also necessary. Caching surely can improve performance by a huge factor, but if it starts behaving abnormally, it can take down the whole infrastructure.
In the case of Redis, use commands like INFO, MONITOR, or third-party tools to monitor cache health, eviction rates, and hit/miss ratios. Optimizing TTLs and cache eviction policies (LRU, LFU, etc.) can be useful.
Avoiding Dog-pile Effect
The dog-pile effect in caching occurs when multiple requests simultaneously attempt to regenerate a cache entry after it expires. This can overwhelm the backend system and degrade performance.
Avoiding this is not as simple, and I need a full article. For now, Google and AI tools should be used to work around this. As a concise checklist, I can’t do justice to this topic by squeezing it here.
Conclusion
Caching, if done correctly, is a powerful accelerator for your backend infrastructure. By keeping these points in mind, you can make sure that your cache implementations remain consistent and perform as expected.
Will see you in my next article, bye!